Update: Quanta Magazine posted an article about our result as well.
Jacques Verstraete and I posted a preprint on the arXiv today on the off-diagonal Ramsey number  . In short, we show that
. In short, we show that  , which is just a
, which is just a  factor shy from the upper bound
factor shy from the upper bound  proved by Ajtai, Komlós and Szemerédi in 1980. Erdős [1] conjectured that up to logarithmic factors,
proved by Ajtai, Komlós and Szemerédi in 1980. Erdős [1] conjectured that up to logarithmic factors,  is the order of growth:
is the order of growth:

We thus confirm this conjecture. The previous best lower bound was due to Bohman and Keevash who studied the random 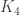 -free process and obtained
-free process and obtained  , where the tilde hides logarithmic factors. It is not clear whether our methods can be pushed further to obtain asymptotically sharp bounds. In any case, that’s not what I want to speculate about, but rather sketch the proof of our result. It’s in my very biased opinion a nice combination of ideas that existed in the literature before, but have each been slightly sharpened for our particular application. So without further ado, here are the four main steps with some explanation and the elevator pitch for each.
, where the tilde hides logarithmic factors. It is not clear whether our methods can be pushed further to obtain asymptotically sharp bounds. In any case, that’s not what I want to speculate about, but rather sketch the proof of our result. It’s in my very biased opinion a nice combination of ideas that existed in the literature before, but have each been slightly sharpened for our particular application. So without further ado, here are the four main steps with some explanation and the elevator pitch for each.
1. Construct an algebraically defined graph
The graph we start out with is in fact not -free. However, it is good enough in the sense that it does not contain any “non-degenerate” copies of . This means the following: the vertex set of the graph is a subset of nearly all lines in  , in the sense that this subset has size
, in the sense that this subset has size  , adjacent if and only if they intersect in a point belonging to a special subset
, adjacent if and only if they intersect in a point belonging to a special subset  of points. No “non-degenerate” copies of then refers to the fact that there are no four lines in general position (i.e. no three concurrent) which pairwise intersect in distinct points of .
of points. No “non-degenerate” copies of then refers to the fact that there are no four lines in general position (i.e. no three concurrent) which pairwise intersect in distinct points of .
Anurag provides some more geometrical details on his blog, but here’s a short summary. The point set is the set of points of a Hermitian unital and the “no non-degenerate of lines” refers to the fact that one cannot find an O’Nan configuration, which is a set of four  -secants pairwise intersecting in distinct points of the unital. In the incidence graph of -secants and
-secants pairwise intersecting in distinct points of the unital. In the incidence graph of -secants and  this correponds to a subdivision of , see the pictures below.
this correponds to a subdivision of , see the pictures below.

The O’Nan configuration (left) and the subdivision of with vertices corresponding to lines marked in red (right).
This property is quite remarkable for several reasons. The fact that we know that there are no O’Nan configurations was first observed by O’Nan in 1972 as a byproduct from his study on the unitary group  . I dare say that extremal graph theory was not on his mind when he wrote this down.
. I dare say that extremal graph theory was not on his mind when he wrote this down.
Secondly, I know of no other geometry which has a similar feature with respect to . Generalized quadrangles have this feature with respect to 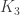 , i.e. copies of in its collinearity graph always consist of three collinear points and are hence degenerate, but I’m not familiar with any geometry avoiding non-degenerate
, i.e. copies of in its collinearity graph always consist of three collinear points and are hence degenerate, but I’m not familiar with any geometry avoiding non-degenerate 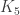 . In fact, returning to unitals and , it is conjectured that every unital (sets of points with the same intersection pattern as a Hermitian unital) apart from the Hermitian one contains O’Nan configurations, so the Hermitian unital really is special.
. In fact, returning to unitals and , it is conjectured that every unital (sets of points with the same intersection pattern as a Hermitian unital) apart from the Hermitian one contains O’Nan configurations, so the Hermitian unital really is special.
Thirdly, apart from the recent [2], I know of no other works in extremal graph theory where Hermitian varieties (defined by sesquilinear forms) pop up instead of the more familiar quadrics, or more generally graphs defined by bilinear forms such as [3] and [7] to name two.
Conclusion. We have a graph on vertices with some nice properties and no “non-degenerate” copies of .
Takeaway. Hermitian unitals are neat in general, but having no O’Nan configurations is a bit of a miracle.
2. Make it -free
Another interesting fact about this graph is that its edge set is a union of maximal cliques which pairwise intersect in at most a vertex. Moreover, by the discussion in the previous section, any copy of has at least three vertices in the same maximal clique. This means we can do the same thing as David Conlon [3] when he constructed triangle-free graphs from generalized quadrangles: randomly cut the maximal cliques in half and replace them by complete bipartite graphs. In this way, we can get rid of all copies of . The difficulty is to preserve the pseudorandomness properties of the graph which we will need later on. In order to do so, we analyze this process using martingales and the Azuma-Hoeffding inequality, which improves on David’s analysis, which uses the Hanson-Wright inequality. This adheres to the intuition that one can achieve better control of a random process by analyzing it step-by-step instead of analyzing the final result. I’ll happily refer to the preprint for the technical details.
Conclusion. We have a -free graph on vertices with some nice pseudorandomness properties.
Takeaway. Slowing down the random cutting process can improve concentration inequalities.
3. Count the number of independent sets of a given size
In previous work, this step was executed using a spectral approach based on the expander mixing lemma, which was originally due to Alon and Rödl [4]. However, this approach is not robust enough in the following sense: ideally, for this approach to work, you’d like all non-trivial eigenvalues of your graph to be bounded in absolute value by  , where
, where  and
and  is the regularity of the graph you are working with.
is the regularity of the graph you are working with.
However, in our case, two problems arise. The first one is that the eigenvalues of our graph are  and
and  . While
. While 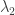 is great in comparison to , the eigenvalue
is great in comparison to , the eigenvalue 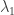 , even though its multiplicity is very small, ruins the day. Nevertheless, the smallest eigenvalue should be the one governing independent sets, as is known in algebraic graph theory (see e.g. the ratio bound), so somehow this awful shouldn’t matter.
, even though its multiplicity is very small, ruins the day. Nevertheless, the smallest eigenvalue should be the one governing independent sets, as is known in algebraic graph theory (see e.g. the ratio bound), so somehow this awful shouldn’t matter.
Secondly, whatever nice regularity properties we have of our original graph — indeed, it is in fact a strongly regular graph — once we randomly cut the maximal cliques, we no longer get to use this. It seems to be harder to analyze the eigenvalues of the post-cut graph than to investigate another measure of pseudorandomness, which is the one we used in the end. However, it would be nice if one could attain some control over the eigenvalues of the resulting graph and show perhaps that the smallest eigenvalue is still close to  .
.
The pseudorandomness measure we proved in the end was some supersaturation, i.e. the fact that any subset of vertices of size  , for large constant
, for large constant  , spans many edges. One could also refer to this property as one-sided jumbledness. In this context, it must be remarked that the size of the largest independent set is exactly
, spans many edges. One could also refer to this property as one-sided jumbledness. In this context, it must be remarked that the size of the largest independent set is exactly  . This supersaturation property suffices to run another algorithm for counting independent sets, which nowadays falls under the umbrella of graph containers, but dates back to seminal work of Kleitman and Winston from 1980. We refer to the survey by Samotij [5] for an excellent overview of this topic.
. This supersaturation property suffices to run another algorithm for counting independent sets, which nowadays falls under the umbrella of graph containers, but dates back to seminal work of Kleitman and Winston from 1980. We refer to the survey by Samotij [5] for an excellent overview of this topic.
This step is where we lose the logarithmic factors: ideally we would like to show that the number of independent sets of size  is
is  . Unfortunately, we can only count the independent sets of size slightly bigger, namely
. Unfortunately, we can only count the independent sets of size slightly bigger, namely  . Somehow, this extra
. Somehow, this extra  factor pops up both in the Alon-Rödl and the Kleitman-Winston approaches, which might not be that much of a surprise to experts since the counting algorithms are quite similar in some sense. Nevertheless, it indicates that new ideas will be necessary to get rid of the extra logarithmic factors here.
factor pops up both in the Alon-Rödl and the Kleitman-Winston approaches, which might not be that much of a surprise to experts since the counting algorithms are quite similar in some sense. Nevertheless, it indicates that new ideas will be necessary to get rid of the extra logarithmic factors here.
Conclusion. We have a -graph on vertices with at most  independent sets of size
independent sets of size  .
.
Takeaway. Containers give you the same count as a spectral approach but are more flexible.
4. Randomly sample a subgraph
This step is the same as in Jacques’ previous paper with Dhruv Mubayi [6] where one uniformly and independently samples vertices with probability chosen in order to destroy all independent sets of size . In this case, the probability is  and we arrive at a -free graph on
and we arrive at a -free graph on  vertices containing no independent set of size
vertices containing no independent set of size  . This proves that
. This proves that  .
.
Conclusion. That’s all folks!
Takeaway. Randomly sampling a subgraph can destroy unwanted configurations if there are few of them, see also the multicolor Ramsey breakthrough by Conlon and Ferber [7].
References
[1] P. Erdős. Problems and results on graphs and hypergraphs: similarities and differences, in Mathematics of Ramsey theory, Algorithms Combin., Vol. 5 (J. Nesetfil and V. Rodl, eds.), 12-28. Berlin: Springer-Verlag, 1990.
[2] Bamberg, J., Bishnoi, A. and Lesgourgues, T. (2022), The minimum degree of minimal Ramsey graphs for cliques. Bull. London Math. Soc., 54: 1827-1838. https://doi.org/10.1112/blms.12658
[3] D. Conlon, A sequence of triangle-free pseudorandom graphs. Combin. Probab. Comput. 26 (2017), no. 2, 195–200.
[4] N. Alon, V. Rödl, Sharp bounds for some multicolor Ramsey numbers. Combinatorica 25 (2005), no. 2, 125–141.
[5] W. Samotij, Counting independent sets in graphs, European Journal of Combinatorics, Volume 48, 2015, Pages 5-18.
[6] D. Mubayi, J. A. Verstraete, A note on pseudorandom Ramsey graphs, J. Eur. Math. Soc. (10 pages).
[7] D. Conlon, A. Ferber, Lower bounds for multicolor Ramsey numbers, Advances in Mathematics, Volume 378, 2021, 107528.


Reblogged this on Combinatorics and more.
LikeLike