Over the past few months, I have been working on some project regarding flags in finite geometries with Jan De Beule and Klaus Metsch. A preprint on this should appear in the near future. In any case, there is plenty of material that does not quite fit into what we did, but seemed interesting nonetheless. Therefore, I’ll post it here.
First of all, we need to recall the definition of a flag in an incidence geometry and its type. There are exact definitions of ‘flag’, ‘incidence geometry’, and ‘type’, but since we consider rather natural geometries, I will not bother to state them. Instead, it suffices to know that a flag is a set of elements in the incidence geometry that are pairwise incident. An example illuminates this best.
Example. Consider the the set 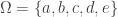 , then a natural incidence geometry on this ground set has as elements all subsets of
, then a natural incidence geometry on this ground set has as elements all subsets of  and containment as the incidence relation. The type of an element is the size of the subset. Then the set
and containment as the incidence relation. The type of an element is the size of the subset. Then the set  is a flag of type
is a flag of type 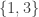 in this geometry, just as
in this geometry, just as  is one of type
is one of type 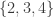 .
.
The easiest flags to handle are those of of size one and a lot is known when we are dealing with flags of size one. In the previous example these are just the subsets of . We could investigate the flags of type  , which boils down to the Johnson scheme
, which boils down to the Johnson scheme  , where all possible relations between two flags of type are
, where all possible relations between two flags of type are  . A symmetric and commutative algebra appears when we consider the vector space spanned by the adjacency matrices of these relations, which is called an association scheme.
. A symmetric and commutative algebra appears when we consider the vector space spanned by the adjacency matrices of these relations, which is called an association scheme.
In our case, we are interested in subspaces of 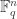 . When considering only
. When considering only  -dimensional subspaces, the natural relations depend on the dimension of the intersection of two such spaces. The algebra one derives from this is again symmetric and commutative is often called the
-dimensional subspaces, the natural relations depend on the dimension of the intersection of two such spaces. The algebra one derives from this is again symmetric and commutative is often called the  -Johnson scheme
-Johnson scheme 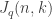 , as it is a -analog. Again, when we want to consider flags of subspaces, things quickly get more complicated.
, as it is a -analog. Again, when we want to consider flags of subspaces, things quickly get more complicated.
In general, the symmetry of the algebras  and is easy to see, since the relations on flags of size one themselves are symmetric. Since an algebra of symmetric matrices is commutative, the latter also follows. When we consider larger flags however, symmetry is immediately gone. One can wonder what remains of the commutativity.
and is easy to see, since the relations on flags of size one themselves are symmetric. Since an algebra of symmetric matrices is commutative, the latter also follows. When we consider larger flags however, symmetry is immediately gone. One can wonder what remains of the commutativity.
In the two cases we mention, this problem is in fact solved (in disguise) by Godsil and Meagher. When we consider not just flags in vector spaces, but also flags in polar and parapolar spaces and other geometries, building theory pops up, and this has been handled by Abramenko, Parkinson and Van Maldeghem, with different methods.
Buildings, or what I understand of it, are a very natural framework to investigate flags in classical incidence geometries. Although we restrict ourselves to spherical irreducible buildings, this class is already rich enough to obtain the results we are interested in. We will focus on the commutativity of the association scheme on flags of subsets of ![[n] = \{1,\dots,n\}](https://s0.wp.com/latex.php?latex=%5Bn%5D+%3D+%5C%7B1%2C%5Cdots%2Cn%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) . The remarkable strength of building theory is that it allows the exact same result to be transferred to flags of subspaces in !
. The remarkable strength of building theory is that it allows the exact same result to be transferred to flags of subspaces in !
The result for flags of subsets of states that the association scheme (or adjacency algebra) is commutative only for flags of size one, hence only for the Johnson scheme , for some 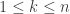 . In the article by Godsil and Meagher, this is proven using some character theory. We will sketch a purely combinatorial proof here, based on the combinatorics of compositions and partitions.
. In the article by Godsil and Meagher, this is proven using some character theory. We will sketch a purely combinatorial proof here, based on the combinatorics of compositions and partitions.
Consider the symmetric group 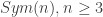 generated by the adjacent transpositions
generated by the adjacent transpositions  . It can be checked that the relations between the generators are
. It can be checked that the relations between the generators are  ,
, 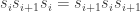 for
for  and
and  if
if  . Moreover, it turns out that this is presentation for
. Moreover, it turns out that this is presentation for  . We can now reconstruct the association scheme as the association scheme with relations the orbitals (orbits on pairs) of on the -subsets of
. We can now reconstruct the association scheme as the association scheme with relations the orbitals (orbits on pairs) of on the -subsets of ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) . In fact, there is quite some redundancy there, as we do not need the full group , but can restrict ourselves to the stabilizer of a single -subset. One can easily see that for the -subset
. In fact, there is quite some redundancy there, as we do not need the full group , but can restrict ourselves to the stabilizer of a single -subset. One can easily see that for the -subset 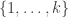 , the stabilizer is the subgroup generated by
, the stabilizer is the subgroup generated by  . Now this subgroup is a Young subgroup
. Now this subgroup is a Young subgroup  .
.
This construction holds for the association scheme of flags of any type. For each flag there is a corresponding Young subgroup, and every Young subgroup corresponds to a composition of (a set of non-negative integers summing to  ). In the example above, this is the composition
). In the example above, this is the composition  . The commutativity of the association scheme is encoded in the induction of the trivial character
. The commutativity of the association scheme is encoded in the induction of the trivial character  of the Young subgroup
of the Young subgroup  to . It is commutative if and only if this character is multiplicity-free, i.e. every irreducible character of appears with multiplicity 0 or 1 in the decomposition. Here comes the kicker: the irreducible representation of are parametrized by partitions (compositions with the parts ordered in non-decreasing way) of , and the multiplicities of can be computed in a purely combinatorial way depending on these two compositions!
to . It is commutative if and only if this character is multiplicity-free, i.e. every irreducible character of appears with multiplicity 0 or 1 in the decomposition. Here comes the kicker: the irreducible representation of are parametrized by partitions (compositions with the parts ordered in non-decreasing way) of , and the multiplicities of can be computed in a purely combinatorial way depending on these two compositions!
These coefficients are called Kostka numbers, and for our purpose it suffices to know whether they are larger than 1 or not. This becomes rather easy if you know how to compute them combinatorially: given a partition  of , i.e. ordered such that
of , i.e. ordered such that  , you can picture its Young tableau, a collection of left-aligned boxes with
, you can picture its Young tableau, a collection of left-aligned boxes with 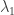 in the first row,
in the first row, 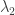 in the second row and so on. Now given another composition
in the second row and so on. Now given another composition  you want to fill in the boxes of Young tableau above with
you want to fill in the boxes of Young tableau above with 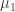 times the number 1,
times the number 1,  times the number 2 and so on, in such a way that the rows are non-decreasing and the columns strictly increasing. The number of ways you can do this is the Kostka number
times the number 2 and so on, in such a way that the rows are non-decreasing and the columns strictly increasing. The number of ways you can do this is the Kostka number  .
.
Since  , where
, where  is the irreducible character corresponding to the partition
is the irreducible character corresponding to the partition  and is a Young subgroup corresponding to the composition
and is a Young subgroup corresponding to the composition  , we need to find out for which there exists such that
, we need to find out for which there exists such that  . When has only two parts, it is easy to see that this can never occur. However, when has at least three parts, it is a nice exercise to see that there is always at least one composition such that .
. When has only two parts, it is easy to see that this can never occur. However, when has at least three parts, it is a nice exercise to see that there is always at least one composition such that .
The conclusion is that for flags of subsets or subspaces, we never find a commutative association scheme, except for flags of size one. This means that a lot of tools of commutative association schemes will not work anymore for more general flags other techniques are needed to overcome this difficulty.

 . In short, we show that
. In short, we show that  , which is just a
, which is just a  factor shy from the upper bound
factor shy from the upper bound  proved by Ajtai, Komlós and Szemerédi in 1980. Erdős [1] conjectured that up to logarithmic factors,
proved by Ajtai, Komlós and Szemerédi in 1980. Erdős [1] conjectured that up to logarithmic factors,  is the order of growth:
is the order of growth:
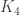 -free process and obtained
-free process and obtained  , where the tilde hides logarithmic factors. It is not clear whether our methods can be pushed further to obtain asymptotically sharp bounds. In any case, that’s not what I want to speculate about, but rather sketch the proof of our result. It’s in my very biased opinion a nice combination of ideas that existed in the literature before, but have each been slightly sharpened for our particular application. So without further ado, here are the four main steps with some explanation and the elevator pitch for each.
, where the tilde hides logarithmic factors. It is not clear whether our methods can be pushed further to obtain asymptotically sharp bounds. In any case, that’s not what I want to speculate about, but rather sketch the proof of our result. It’s in my very biased opinion a nice combination of ideas that existed in the literature before, but have each been slightly sharpened for our particular application. So without further ado, here are the four main steps with some explanation and the elevator pitch for each.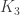 -subgraphs in a rank 2 polar space consist of 3 collinear points. It’s not hard to then make a triangle-free graph out of its collinearity graph: remove edges to transform every maximal clique in a complete bipartite graph. Doing it randomly preserves the ‘random-like’ properties of the original graph, which in this case is stated in terms of jumbledness (see the paper for a definition). This only works for rank 2 though, as maximal cliques, being lines, intersect in at most a point. Once the rank increases, we no longer have this independence of colorings which is crucial for the analysis of the random process.
-subgraphs in a rank 2 polar space consist of 3 collinear points. It’s not hard to then make a triangle-free graph out of its collinearity graph: remove edges to transform every maximal clique in a complete bipartite graph. Doing it randomly preserves the ‘random-like’ properties of the original graph, which in this case is stated in terms of jumbledness (see the paper for a definition). This only works for rank 2 though, as maximal cliques, being lines, intersect in at most a point. Once the rank increases, we no longer have this independence of colorings which is crucial for the analysis of the random process.  -graphs) triangle-free graphs of density
-graphs) triangle-free graphs of density 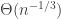 , but interestingly, he uses an atypical generalized quadrangle, in the sense that it does not belong to a classical family of polar spaces. It can also be done in the classical case, in particular I have an unpublished construction for
, but interestingly, he uses an atypical generalized quadrangle, in the sense that it does not belong to a classical family of polar spaces. It can also be done in the classical case, in particular I have an unpublished construction for 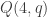 ,
,  , which seems to not extend to higher ranks.
, which seems to not extend to higher ranks.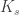 -free graphs based on the observation that no
-free graphs based on the observation that no 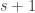 vectors can be pairwise orthogonal in an
vectors can be pairwise orthogonal in an  -dimensional vector space. Orthogonality in the setting of vector spaces over finite fields is defined by bilinear forms as usual, but one needs to take care to remove the self-orthogonal vectors, or rather one-dimensional spaces which projectively are points. The improvements given above use the fact that one can talk roughly half of the projective points to also avoid any
-dimensional vector space. Orthogonality in the setting of vector spaces over finite fields is defined by bilinear forms as usual, but one needs to take care to remove the self-orthogonal vectors, or rather one-dimensional spaces which projectively are points. The improvements given above use the fact that one can talk roughly half of the projective points to also avoid any  subgraphs. When the field size
subgraphs. When the field size 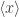 depending on whether its evaluation
depending on whether its evaluation  is square or non-square. When
is square or non-square. When  of the Turán number of
of the Turán number of 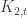 . His construction relies on a clever ‘folding’ of the polarity graph which was known to be sharp for
. His construction relies on a clever ‘folding’ of the polarity graph which was known to be sharp for 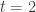 . However, the same idea was already known to
. However, the same idea was already known to  and
and  be a set of
be a set of  and the only examples attaining equality are the point-pencils (i.e. all
and the only examples attaining equality are the point-pencils (i.e. all  be a
be a  -regular graph on
-regular graph on 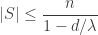 .
. , where
, where 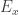 denotes the eigenspace corresponding to the eigenvalue
denotes the eigenspace corresponding to the eigenvalue  (of the adjacency matrix of
(of the adjacency matrix of 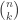 vertices of valency
vertices of valency 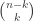 . One can show that the smallest eigenvalue is
. One can show that the smallest eigenvalue is  (we will not prove this). After a small computation, one immediately deduces the bound in the EKR theorem.
(we will not prove this). After a small computation, one immediately deduces the bound in the EKR theorem. such that every induced subgraph on
such that every induced subgraph on  ,
,  is a biregular graph and the induced subgraph on every
is a biregular graph and the induced subgraph on every  is regular. Such a partition is called an equitable partitition.
is regular. Such a partition is called an equitable partitition. 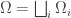 is the
is the  matrix
matrix  , where
, where  is the number of neighbours in
is the number of neighbours in  a vertex in
a vertex in  is an eigenvector of
is an eigenvector of  by setting
by setting  , whenever
, whenever 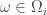 . This vector will also be an eigenvector of the adjacency matrix of
. This vector will also be an eigenvector of the adjacency matrix of  .
.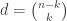 , and
, and  , which we recall is the smallest eigenvalue! Their multiplicities as eigenvalues of
, which we recall is the smallest eigenvalue! Their multiplicities as eigenvalues of  and
and  (a fact which we will again not prove). Here comes the essence of the technique: since
(a fact which we will again not prove). Here comes the essence of the technique: since 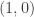 is in its rowspace and is hence a lineair combination of eigenvectors corresponding to
is in its rowspace and is hence a lineair combination of eigenvectors corresponding to 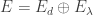 , and it is not too hard to show that they are in fact linearly independent and hence form a basis of
, and it is not too hard to show that they are in fact linearly independent and hence form a basis of  . In other words, (the characteristic vectors of) the point-pencils are a basis of this space. From here on out, it is again not too difficult (see the Godsil-Meagher book p.123 for the details) to show that there are no other maximal intersecting families in this eigenspace, from which the classification follows.
. In other words, (the characteristic vectors of) the point-pencils are a basis of this space. From here on out, it is again not too difficult (see the Godsil-Meagher book p.123 for the details) to show that there are no other maximal intersecting families in this eigenspace, from which the classification follows.