
Last week, I gave a seminar on the slice rank of functions (probably one of many concerning that particular subject since last year). The motivation being mainly that I, together with my advisors Jan De Beule and Philippe Cara, wanted to understand this method better, so what better way to understand something than to talk about it with fellow mathematicians?
I want to write down some of the material I presented on the blackboard, primarily to have a reference and some notes for myself, but perhaps they can also give someone else a better understanding of the ideas and concepts regarding this topic. I have not seen the visual interpretation of the different notions of rank is anywhere else, so this might be interesting as well. Let me know if this has helped you or if something needs more explanation!
Background
Last year, the combinatorial world was stunned by a series of results by Croot-Lev-Pach, Ellenberg-Gijswijt regarding arithmetic progressions in certain groups. I will not try and give an complete account of these, as several sources around the web have done so already quite extensively (blog post by Anurag Bishnoi; a rendition of the proof by Doron Zeilberger and references on Gil Kalai’s blog). As an indicator of the gravity of these two results, both have been published in the Annals of Mathematics in the beginning of this year. Instead, I will try to elude the idea of ‘slice rank’ of a tensor, as was defined by Terry Tao in his reformulation of the Ellenberg-Gijswijt proof. I will try to indicate where the idea might have come from and how one can understand it in a sort of geometrical way. Most, if not all, of the theory can be developed for general tensors (see again Terry’s blog), but we will restrict ourselves to to a special case, which we will explain in the next paragraph. The reason for this is that I find the concepts easier to explain in this specific setting. So without further ado, let’s get on with it.
Functions of a finite set to a field
People comfortable with tensor products and know why an n-variable function 

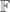
For those who aren’t (like myself), here’s a short explanation why. Consider a finite set 


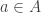

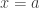

Therefore, for two finite sets 

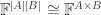


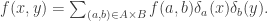
In the same way, one can write 
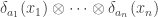
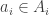
Tensor rank versus (multi-)slice rank
For most instances of ‘rank of an object’, we have the following heuristic rule:
object of rank k = sum of k objects of rank one (and not less)
Meaning that, in order to define a rank function, it suffices to specify the rank one objects. This is for example the case for the usual definition of tensor rank, and will also be the case for the other two rank functions we define. As previously remarked, we will only define these rank function for the special case of n-variable functions.
In order to avoid cumbersome notation, we use the following convention. Let ![[n] = \{1,\dots,n\}](https://s0.wp.com/latex.php?latex=%5Bn%5D+%3D+%5C%7B1%2C%5Cdots%2Cn%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![I = \{i_1,\dots,i_k\} \subseteq [n]](https://s0.wp.com/latex.php?latex=I+%3D+%5C%7Bi_1%2C%5Cdots%2Ci_k%5C%7D+%5Csubseteq+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)

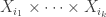
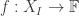
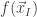
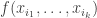
A function ![f(\vec{x}_{[n]}): X_{[n]} \rightarrow\mathbb{F}](https://s0.wp.com/latex.php?latex=f%28%5Cvec%7Bx%7D_%7B%5Bn%5D%7D%29%3A+X_%7B%5Bn%5D%7D+%5Crightarrow%5Cmathbb%7BF%7D&bg=ffffff&fg=333333&s=0&c=20201002)

![f(\vec{x}_{[n]}) = g_1(x_1)\dots g_n(x_n)](https://s0.wp.com/latex.php?latex=f%28%5Cvec%7Bx%7D_%7B%5Bn%5D%7D%29+%3D+g_1%28x_1%29%5Cdots+g_n%28x_n%29&bg=ffffff&fg=333333&s=0&c=20201002)
A function 
![g:X_i \rightarrow\mathbb{F}, h:X_{[n]\backslash \{i\}}](https://s0.wp.com/latex.php?latex=g%3AX_i+%5Crightarrow%5Cmathbb%7BF%7D%2C+h%3AX_%7B%5Bn%5D%5Cbackslash+%5C%7Bi%5C%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![f(x_{[n]}) = g(x_i)h(x_{[n]\backslash \{i\}})](https://s0.wp.com/latex.php?latex=f%28x_%7B%5Bn%5D%7D%29+%3D+g%28x_i%29h%28x_%7B%5Bn%5D%5Cbackslash+%5C%7Bi%5C%7D%7D%29&bg=ffffff&fg=333333&s=0&c=20201002)
A function ![I \subseteq [n]](https://s0.wp.com/latex.php?latex=I+%5Csubseteq+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![g:X_I \rightarrow\mathbb{F}, h:X_{[n] \backslash I}](https://s0.wp.com/latex.php?latex=g%3AX_I%C2%A0%5Crightarrow%5Cmathbb%7BF%7D%2C+h%3AX_%7B%5Bn%5D+%5Cbackslash+I%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![f(x_{[n]}) = g(x_I)h(x_{[n] \backslash I})](https://s0.wp.com/latex.php?latex=f%28x_%7B%5Bn%5D%7D%29+%3D+g%28x_I%29h%28x_%7B%5Bn%5D+%5Cbackslash+I%7D%29&bg=ffffff&fg=333333&s=0&c=20201002)
Bounds and examples
Let ![f: X^{[n]} \rightarrow \mathbb{F}](https://s0.wp.com/latex.php?latex=f%3A+X%5E%7B%5Bn%5D%7D+%5Crightarrow+%5Cmathbb%7BF%7D&bg=ffffff&fg=333333&s=0&c=20201002)
multi-slice rank(

A decomposition of
slice rank(

tensor rank(

and if ![g: X^{[n]} \rightarrow \mathbb{F}](https://s0.wp.com/latex.php?latex=g%3A+X%5E%7B%5Bn%5D%7D+%5Crightarrow+%5Cmathbb%7BF%7D&bg=ffffff&fg=333333&s=0&c=20201002)
multi-slice rank(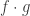


These bounds can be found in the papers of Blasiak et. al and Naslund.
We can show some examples to see that tensor rank, slice rank and multi-slice rank may differ heavily. Let 
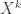
Example 1. Consider the function
which is 1 if
and 0 otherwise. Define
. This function has tensor rank
and slice rank 1.
This example shows that the second inequality is sharp. The gap between slice rank and multi-slice rank can also be big, as shown in the next example.
Example 2. Define
. This function has slice rank
Visually representing the differences
Clearly for 



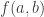
When considering a function 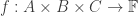
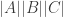
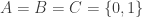

We can first consider the case when a function has tensor rank one. When drawing its associated hypermatrix with the values, we get the following picture.
Figure 1: The function has tensor rank one.
We see that in all three directions, we have ‘scalarity’ (by lack of a better word), by which I mean that (every value on) every hyperplane is a scalar multiple of (a value on) any parallel hyperplane. This clearly also holds if 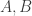

Suppose that the function has slice rank one, then the picture is the following.
Figure 2: The function has slice rank one.
Clearly, the property of scalarity of the hyperplanes in all directions / all parallel classes is now replaced by scalarity of hyperplanes in one direction, namely in the direction indexed by the set whose variable can be split off.
To understand the difference between slice rank and multi-slice rank, using this same idea of a hypermatrix of values, we would need to draw a 4D hypermatrix. We will make an attempt in doing so. We will again consider the simple case when all sets involved are 
A cube in 2D can be drawn as below: draw two squares, one sitting inside the other, and connect corresponding points of the squares.
A 4D cube can be realised in 3D in the same way: take two cubes, one inside the other and connect corresponding points. However, this blog is as of now restricted to two dimensions (high hopes for the distant future!), so we need to draw these two cubes again the in plane. This can be done in the following way.
The blue and red cube are the original cubes, corresponding points are connected by the green lines.
Using this visual representation, we can try to distinguish functions of slice rank one and of multi-slice rank one. First we start with a function of slice rank one and its hypercube of values.
![]()
As you can see, the red and blue cubes, contained in the hypercube, exhibit the scalarity phenomenon. This indeed means that we have scalarity of hyperplanes (which in this case are three-dimensional spaces on the hypercube, i.e. cubes) in one direction. In contrast, below is the hypercube of values for a function of multi-slice rank one.
![]()
In this case, we have scalarity of the red and blue subspace, but in this case the subspaces are planes, as opposed to cubes. The pictured red and blue planes are not the only pair of planes related by scalarity, can you find more?
Applications to combinatorics
The definition of slice rank and multi-slice rank of an n-variable function are not pulled from thin air. They have appeared implicitly in the Croot-Lev-Pach and Ellenberg-Gijswijt paper and are roughly based on the following basic fact.
Fact. Consider a polynomial
one variable of degree
. When we consider
and expand this into a sum of monomials
, we know that for every monomial either
or
.
This means that if we define a two variable function 
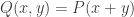
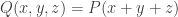
This gives one half of an inequality. The other half comes from a generalization of the fact that the matrix rank of a diagonal matrix is the number of non-zero elements on its diagonal.
Lemma. Let
, let
be a finite set, let
, let
be a coefficient. Then the slice rank of the function
is equal to the number of non-zero coefficients
.
 \mapsto \sum_{a \in A} c_a \delta_a(x_1) \dots \delta_a(x_k) \ \ \ \ \ (2)")
This result was first shown by Tao on his blog and Naslund has extended this by showing that also its multi-slice rank equals the number of non-zero coefficients.
Now how to combine these two ideas? First, have a certain finite set 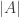
For example in the Ellenberg-Gijswijt paper, one considers the affine space 


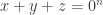
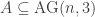

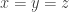

and find bounds for the slice rank of 
