
It’s been a while since I managed to wrap up some projects (moving continents and getting more kids sure does take some time!), but the last few weeks I managed to get some work done. First, the paper with Ishay Haviv, Aleksa Milojević and Yuval Wigderson appeared, and today one with Geertrui Van de Voorde did.
Both of them are essentially applications of the container method to combinatorial problems. I first learned about this method while at UCSD, and indeed, it has been instrumental in the Ramsey result with Jacques (whose published version is now available). Admittedly, my understanding was still rather poor, so I decided to study a bit more last winter. I’ll share some of my newly-gained understanding in the course of summarizing both of these two results.
The container method
Here’s a beautiful summary of the principle of containers from a paper by Gwen McKinley (formerly at USCD while I was there), Asaf Ferber (UC Irvine, just one hour north of UCSD) and Wojciech Samotij (who we’ll meet later):
Roughly speaking, the lemma states that if the edges of a uniform hypergraph 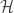

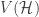
In other words, the container method aims to construct subsets of the vertex set of a (hyper)graph
(1) are few,
(2) induce few (hyper)edges, and,
(3) every independent set of
Each subset of conditions is easily satisfied on its own, and the real strength of the container method is to combine all three. So while the idea is rather simple, the machinery behind it is quite involved and it took some time before its significance was realized. Indeed, the idea goes all the way back to 1980 when Kleitman and Winston used it for graphs to count graphs without 4-cycles. Then rather recently (not even 10 years ago!), it was generalized to hypergraphs by József Balogh, Rob Morris and Wojciech Samotij, and David Saxton and Andrew Thomason independently. I’ll refer you to the Wikipedia page for more history and references, but I would argue that the impact of these works can hardly be understated. For an extensive list of applications and further developments since these seminal results, I’ll refer you to the same Wikipedia page as before or the ICM survey by the first set of authors.
Just to give you a flavor, and so you understand why it takes some time to digest and understand the method, here’s a sample theorem.
Notation. Let 

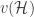

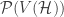
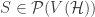
![\mathcal{H}[S]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BH%7D%5BS%5D&bg=ffffff&fg=333333&s=0&c=20201002)
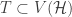


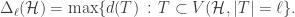
Finally, 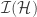
Theorem. For all 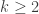
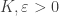
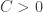
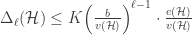

and for some 

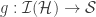

(A) 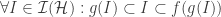
(B) ![\forall S \in \mathcal{S}: e(\mathcal{H}[f(S)]) \leq \varepsilon e(\mathcal{H})](https://s0.wp.com/latex.php?latex=%5Cforall+S+%5Cin+%5Cmathcal%7BS%7D%3A+e%28%5Cmathcal%7BH%7D%5Bf%28S%29%5D%29+%5Cleq+%5Cvarepsilon+e%28%5Cmathcal%7BH%7D%29&bg=ffffff&fg=333333&s=0&c=20201002)
To fully understand this theorem, I will refer you to the excellent lectures by Wojciech Samotij at IBS last winter, but let’s see why it implies the three conditions mentioned before. Given a hypergraph 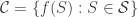
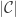

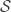
There are many versions and pre-packaged theorems which one can apply to the problem at hand, but it’s hard to see the forest for the trees in the beginning. I can highly recommend the aforementioned video lectures if you want to get into more details, along with Rob Morris’ lecture notes.
Applications
A first immediate application of these theorems is that one can upper bound the number of independent sets of a given size, once we can bound the size of the containers. This is useful in itself as Geertrui and I tried to convey in our paper. I suppose mostly finite geometers need to be convinced that this is interesting, since combinatorialists have used this to count Sidon sets, 
We find plenty of instances in finite geometry where the upper bound provided by the container theorem is asymptotically sharp. In particular, given a (hyper)graph coming from finite geometry, with independence number 



where the 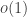


A second application is that we can feed the upper bound on the number of independent sets of given size into the union bound. In this setting, we sample each vertex of the hypergraph 
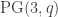
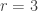
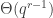
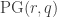
The main difference with the papers referenced above is that we use a different packaged statement of the container method, found in a paper due to Saxton and Thomason. The statement of this theorem is even more involved (see Theorem 5.1 in this paper), so I will not replicate it here. The essence is that after applying the container theorem once, one can iterate it for every container 
![\mathcal{H}[C]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BH%7D%5BC%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\Delta_\ell(\mathcal{H}[C])](https://s0.wp.com/latex.php?latex=%5CDelta_%5Cell%28%5Cmathcal%7BH%7D%5BC%5D%29&bg=ffffff&fg=333333&s=0&c=20201002)
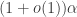
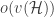
A variation on the same theme is to construct structures with `low independence number’, i.e. the induced hypergraph under consideration has low independence number, by sampling vertices uniformly at random. The idea being that we set the sample probability small enough so that ‘large’ independent sets are destroyed with positive probability. Indeed, this was a crucial step in our proof of the lower bound on 
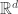
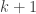
Ishay Haviv and Dror Chawin managed to adapt the argument to prove a similar argument over finite fields. However, they did not use containers and instead devised an ingenious method to count independent sets in the relevant graph. Since this graph was the polarity graph over a finite field, which has featured several times on the blog before, I was curious to see if the container method could be applicable in this case. Indeed, together with Ishay, Aleksa, and Yuval, we managed to extend their results to sets of nearly orthogonal vectors in 
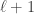
So even though a few gaps in my understanding of containers remain, I’d say that I have gained a pretty functional knowledge over the last few months. It’s a beautiful piece of combinatorics with far-reaching implications and if I can learn how to use it, so can you!
